微服务流程编排之-Netflix Conductor
Conductor是一个微服务的编排引擎
1、背景
网上对netfinx-conductor介绍的文章比较少,最近一直在搭建流程编排引擎服务,所以想对搭建的过程做一个记录,其中遇到的坑,及对源码的改动。也顺便对conductor做一个深入的介绍,方便更多的人使用。 可能有人会有疑问,为什么不进行点对点编排,通过点对点任务编排,我们发现随着业务需求和复杂性的增长难以扩展。发布/订阅模型适用于最简单的流程, 但很快就突出了与该方法相关的一些问题:
- 流程“嵌入”在多个应用程序的代码中。 通常,围绕输入/输出,SLA等存在紧密耦合和假设,使得更难以适应不断变化的需求。 几乎没有办法系统地回答“我们用过程X做了多少”?
2、编排引擎选择
通过学习成本,文档详细程度,社区活跃度等几个方面对比,来选择一种合适的流程编排引擎。
| netflix/conductor | zeebe-io/zeebe | |
|---|---|---|
| 工作流定义方式 | 基于JSON定义工作流有自己的ui界面,可以实时看到工作流处理进度与情况,通过编写json定义工作流、任务等元数据。 | 基于bpmi规范定义工作流,有附带插件性质的bpmi编辑器,配有ui界面能够看到工作流对应的处理情况 |
| 技术栈 | worker 与 引擎之前支持http restful api 和 gRPC,api层与存储层都是可插拔的,已实现redis、mysql、cassandra、postgres四种类型的存储,而且可以自定义扩展,支持zk、redis分布式锁,es数据索引 | worker 与 引擎之间只支持gRPC,数据存储只能维护在本地磁盘,由内部协议保持集群内各个机器数据的一致性(不使用中间件),可以有后续的exporter导出的功能,支持将workflow数据与task导出至es |
| 学习路径 | 文档清晰,社区环境都比较好 | 文档清晰 |
| 运维成本 | 涉及到工作流机器的部署,ui环境部署,数据库、redis,es数据索引 | 工作流机器部署,ui环境部署,es数据索引,数据维护到本地磁盘会有额外的运维成本 |
| 社区活跃度 | 社区活跃,目前在Netflix内部已经实践了一年多,完成数百万个流程的中转 | 社区活跃,发布比较新,2019年秋季发布第一个生产版本,目前时间检验比较少 |
| 数据存储方式 | 支持redis、以及mysql等关系型数据库,可插拔 | 本地磁盘,数据可以导出 |
| 支持的客户端 | 多语言(java、go、python等) | 多语言(java、go、python等) |
| worker与工作流通信协议 | http、gRPC | gRPC |
| 任务与worker的交互方式 | 存储中间件队列,由worker从队列当中定时拉取,执行完毕由worker更新工作流状态,或者由worker触发异步事件 | 支持conductor的轮询模式,同时支持kafka消息驱动模式,即任务完成后发消息,同时直接接受kafka消息驱动流程 |
3、基本概念
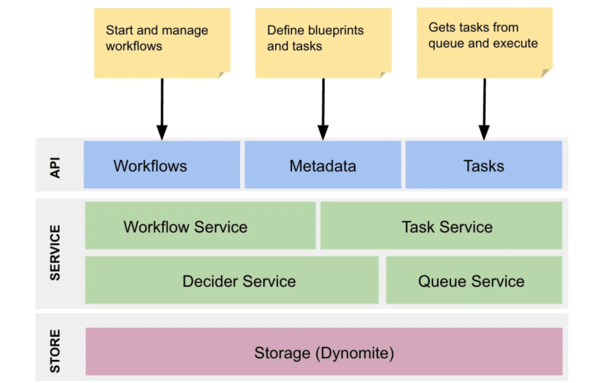
先放两张图,方便对conductor有一个全面的了解。
Conductor整体架构图
一个task执行过程图
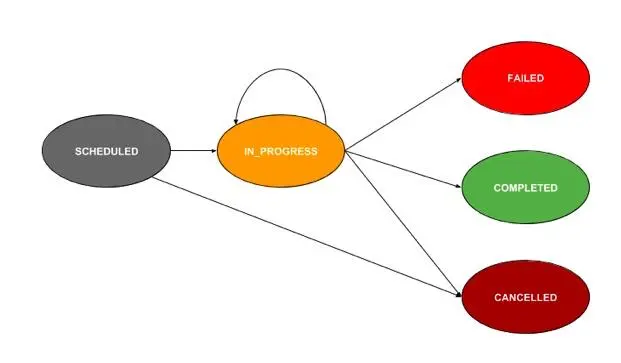
Conductor中关键字:
-
DYNAMIC :基于任务的输入表达式派生的工作任务,而不是静态定义为计划的一部分
-
DECIDE :决策任务 - 实现案例……开关样式分叉
-
FORK:分叉一组并行的任务。计划每个集合并行执行
-
FORK_JOIN_DYNAMIC:与FORK类似,但FORK_JOIN_DYNAMIC不是在并行执行计划中定义的任务集,而是根据此任务的输入表达式生成并行任务
-
JOIN:补充FORK和FORK_JOIN_DYNAMIC。用于合并一个或多个并行分支
-
SUB_WORKFLOW:将另一个工作流嵌套为子工作流任务。在执行时,它实例化子工作流并等待它完成
-
EVENT:在支持的事件系统中生成事件(例如,Conductor,SQS)
4、如何使用
使用之前要明确两个概念,TASK和WORKFLOW,网上的文章比较少,最常看的文档就是官网的 Getting Started guide. TASK是Conductor的最小执行单元,WORKFLOW是串联各TASK形成的完整流程。
- 第一步:选择合适的Conductor版本,然后部署这时你可以通过swaggerUI看到server提供的接口了,页面是这样的:
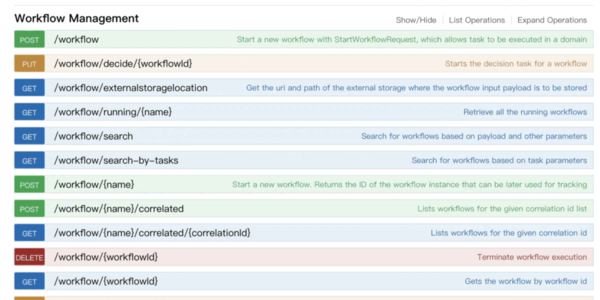
Conductor是前后端分离的,想要看到流程,还要部署一下ui服务,这样才是部署完成。
- 第二步:定义TASK
{
"name": "encode_task",
"retryCount": 3,
"timeoutSeconds": 1200,
"inputKeys": [
"sourceRequestId",
"qcElementType"
],
"outputKeys": [
"state",
"skipped",
"result"
],
"timeoutPolicy": "TIME_OUT_WF",
"retryLogic": "FIXED",
"retryDelaySeconds": 600,
"responseTimeoutSeconds": 3600,
"concurrentExecLimit": 100,
"rateLimitFrequencyInSeconds": 60,
"rateLimitPerFrequency": 50
}
- 第三步:定义一个WORKFLOW
workflow是支持版本控制的,创建时注意版本号的填写,创建workflow时遇到的最多问题是创建的workflow中包含未定义的task。
{
"name": "encode_and_deploy",
"description": "Encodes a file and deploys to CDN",
"version": 1,
"tasks": [
{
"name": "encode",
"taskReferenceName": "encode",
"type": "SIMPLE",
"inputParameters": {
"fileLocation": "${workflow.input.fileLocation}"
}
},
{
"name": "deploy",
"taskReferenceName": "d1",
"type": "SIMPLE",
"inputParameters": {
"fileLocation": "${encode.output.encodeLocation}"
}
}
],
"outputParameters": {
"cdn_url": "${d1.output.location}"
},
"failureWorkflow": "cleanup_encode_resources",
"restartable": true,
"workflowStatusListenerEnabled": true,
"schemaVersion": 2
}
这时你可以在Conductor控台看到这样的页面:
是这样的:
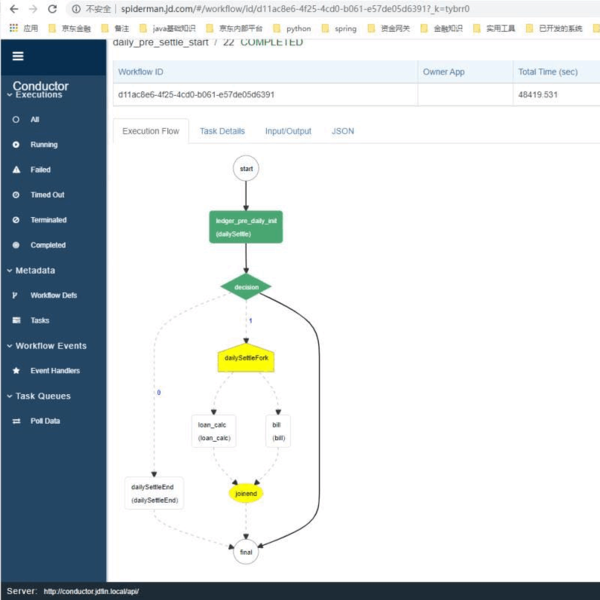
- 第四步:运行一个WORKFLOW
POST http://localhost:8080/api/workflow
{
"name": "myWorkflow", // Name of the workflow
"version": 1, // Version
"correlationId": "corr1", // Correlation Id
"priority": 1, // Priority
"input": { // Input Value Map
"param1": "value1",
"param2": "value2"
},
"taskToDomain": {
// Task to domain map
}
}
当workflow执行完成,各节点会变绿色,当某一个节点卡住或报错了会是红色,节点执行中是黄色
5、做了哪些优化
-
5.1 国外的项目用Gradle比较多,Conductor也是用的Gradle,当时部署服务的第一件事就是把Gradle编译改成了Maven。后面Conductor好像也支持Maven了
-
5.2 添加了conductor-springboot-starter的工具包,方便快速接入,该包主要功能是:a,添加一个@ConductorWorker的注解,使服务中的
TaskHandler自动被扫描到。
<dependency>
<groupId>com.jd.gyl.conductor</groupId>
<artifactId>conductor-springboot-starte</artifactId>
<version>1.1.2</version>
</dependency>
/**
* Created By wanglichao11 At 2019-07-24 11:28
* Desc:该方法是 通获取所有标记ConductorWorker注解的bean,
* 不需要在main中显示的写EnableInitConductor注解,因为在ConductorWorker已经写了
*/
public class InitRegisterWorkers implements ApplicationListener<ContextRefreshedEvent> {
@Value("${config.jd.conductor.url}")
private String rootUrl;
@Value("${config.jd.conductor.thread}")
private int threadCount;
@Value("${config.jd.conductor.queue.size:200}")
private int queueSize;
@Override
public void onApplicationEvent(ContextRefreshedEvent event) {
Map<String, Object> map = event.getApplicationContext()
.getBeansWithAnnotation(ConductorWorker.class);
List<Worker> workList = new ArrayList<>();
TaskClient taskClient = new TaskClient();
//Point this to the server API
taskClient.setRootURI(rootUrl);
// 通过注解获取相关的类
for (Map.Entry<String, Object> entrymap : map.entrySet()) {
try {
// 通过反射获取相关的实现类的Object
Object object = entrymap.getValue();
if (object != null) {
Worker work = (Worker) object;
workList.add(work);
}
} catch (Exception e) {
e.printStackTrace();
}
}
WorkflowTaskCoordinator.Builder builder = new WorkflowTaskCoordinator.Builder();
WorkflowTaskCoordinator coordinator = builder.withWorkers(workList).withThreadCount(threadCount)
.withWorkerQueueSize(queueSize)
.withTaskClient(taskClient).build();
System.out.println("conductor init .............");
coordinator.init();
}
}
- b 方便快速开发,添加一个
AbstractWorker,用来规范每个任务的入参和出参格式ConductorResult,错误形式ConductorException。
public TaskResult execute(Task task) {
TaskResult result = new TaskResult(task);
ConductorResult res;
try {
log.info("开始进入节点 name:{},data:{}", getTaskDefName(), JSON.toJSONString(task.getInputData()));
String req = String.valueOf(task.getInputData().get("req"));
res = doProcess(req);
} catch (Exception e) {
log.error("流程节点错误:{}", getTaskDefName(), e);
result.setStatus(TaskResult.Status.FAILED);
result.getOutputData().put("resultMsg", e.getMessage());
return result;
}
result.setStatus(res.getResultStatus());
result.setCallbackAfterSeconds(res.getCallbackAfterSeconds());
result.getOutputData().put("resultData", JSON.toJSONString(res.getData()));
log.info("流程节点{}完成,data:{}", getTaskDefName(), JSON.toJSONString(res));
return result;
}
-
5.3 conductor的存储组件都是可以插拔的,在配置文件中配置选择,我们当时为了速度,选择了redis + es的存储方式.由于是选择的redis+es的存储方式,还加一个删除
完成状态的workflow的定时任务,用于删除过程数据,结果展示数据在es中,无需删除。 -
5.4 添加了redis锁,conductor一开始的时候没有锁,现在看已经都支持了,zookeeper和redis都支持了,
-
5,5 conductor中保存数据是用的线程池队列,当并发数据量大的时候,队列会溢出,这里修改为使用的mq。(注意mq会有顺序的问题,要加版本号控制,否则会出现,流程执行完成,展示为完成。)
6、压测情况
- 单台120并发,单服务器800tps,正确率999,耗时70-120ms
- 生产环境部署了生产环境12台4c8g虚机,最高可达24000tps
官方文档中文翻译:https://github.com/0532/conductor-document
下一章:Conductor使用中踩过的坑II
